
Quantum Crypto Part 1
13 Mar 2018This is the first in a series of blog posts that make up my final report for the Fall 2015 session of the Quantum Information and Quantum Computing course offered at Georgia Tech. It is presented here as an reference for theoretical Quantum Cryptography, as well as an increasingly out of date survey of experimental methods in the field. This post introduces the idea of Quantum Cryptography, and provides a brief overview of traditional cryptography.
It was Feynman who, in 1982, proposed the idea of a universal quantum simulator [1]. The core idea was to use the inherent high dimensionality of quantum mechanical systems in order to perform a large number of computations in a short amount of time, which would allow such simulators to trace the evolution of other quantum systems in a span of time that could be considered practical. They can do this because of a quantum mechanical concept superposition, wherein a single quantum particle may be in two states at once. This means that a system of $n$ qubits can effectively occupy $2^n$ states, giving rise to the speedup seen over classical computers. In this manner, the essential features of quantum mechanics were shown to provide a way in which one could work around the limitations imposed on us by quantum mechanics (the difficulty of simulating quantum systems with and exponentially increasing number of states).
The world as we know it today relies heavily on cryptography. The ubiquity of access to the internet combined with the requirements of trust imposed by the need for secure multi-party communication across the globe present a problem that is solved quite naturally using techniques from classical cryptography. Most of these tools have at their heart a reliance on the difficulty (under present conditions of mathematical and computational understanding) of solving certain problems; known formally as the cryptographic hardness assumption. Some of these problems include scaled up versions of common exercises given to children in middle school: factoring an integer into its constituent primes. Others involve tasks in more esoteric mathematical settings; finding $e^{th}$ roots of a given number modulo a large number $N$ (The RSA Problem), or finding the logarithm of an element of a group with respect to another element of the group as a base (The Discrete Logarithm Problem). Each of these problems has been studied extensively, to the point where we can confidently say that for certain reasonable parameters of the above problem, it is infeasible for an computationally limited adversary to solve the problem in a reasonable amount of time, ensuring the security of the cryptographic system used[2].
The development of fast quantum algorithms for a number of problems has therefore posed an interesting challenge to the computational assumptions made by cryptographers in analyzing cryptographic systems. For instance, the RSA cryptosystem relies on the difficulty of finding arbitrary roots of a number in a modular setting when the prime factors of the modulus are not known. In general, this problem is easier than integer factorization, which means that an efficient algorithm to factorize integers will allow an efficient solution of the RSA problem - it is almost trivial to find the required roots if the prime factors of the modulus are known. Keeping this in mind, Shor’s success, in 1994, in deducing a method by which an RSA modulus $N$ could be factored in $O\left(lg(N)^{2+o(1)}\right)$ steps using a quantum computer of size $O\left(lg(N)^{1+o(1)}\right)$ essentially sounded a death knell for the RSA system1 [3]. It is enlightening, perhaps, to step back for a moment here and note that practical quantum computers of sufficient size, reliability, and cost parameters that would allow RSA to be broken even by state level actors are quite far off, and that the importance of this result is mostly theoretical at the current time. On the other hand, the prevailing mood in the cryptographic community is to jettison a system as soon as any chink is discovered in its armor, and so a cautious move away from using RSA in production systems is well in order. To illustrate the seriousness of this problem, between $17\%$ and $26\%$ of the top one million websites on the internet (as of January, 2014) support some variant of RSA in their security suites.2 Similarly, fast search algorithms like Grover’s eponymous construction affect almost all cryptographic systems, although the degree to which they are affected depends on the details of the system involved. However, Compared to the massive speed up afforded by Shor’s algorithm in the specific case of RSA, Grover’s algorithm is not nearly as game-changing (It offers a search algorithm that takes $\left(O\sqrt{N}\right)$ time, which, in practical terms, reduces the effective security of the system used by half (Essentially making a 512-bit key only as secure as a 256-bit one)[4]. Shor’s algorithm, on the other hand, decimates the security properties of RSA, requiring keys on the order of $2^{b/2}$ bits in length to provide the same level of security that a $b$ bit key would provide in the absence of Shor’s algorithm, which is an intolerable cost for any practical application.
In the theme of quantum phenomenon opening up new possibilities where it closes old ones, the invalidation of a large portion of the existing cryptographic infrastructure was somewhat alleviated by the discovery that it was possible to use the quantum properties of microscopic objects to transmit information between parties in a manner that is essentially invulnerable to eavesdropping by a third party. The theory surrounding this process will be the meat of this report, examining some of the protocols that have been developed so far, the techniques used to make them practical, and the security implications of some of the features of quantum mechanics that allow us to do all of this with a degree of certainty. Further, we examine experimental realizations of the techniques described in the former half of the paper, providing a measure of proof of the practicality of the notions covered. In conclusion, we discuss some of the limitations of quantum channels and possible directions future work in the area could take.
History
The story of cryptographic systems dates back to time immemorial. Humans have kept secrets for as long as we’ve existed, and have tried to communicate those secrets in a secure manner for as long as language itself has existed. A number of solutions to this problem have arisen over the years, although we shall skip most of the early development of cryptosystems in favor of an overview of the modern cryptographic infrastructure, beginning with a discussion of symmetric and asymmetric cryptography.
We will use the notions of plaintext (the unencrypted message to be transmitted), ciphertext (the encrypted message), and key (some short string that, when combined with the plaintext in a rigorous manner specified by an encryption algorithm, produces the ciphertext) throughout.
Symmetric and Asymmetric Cryptography
At its core, the distinction between symmetric and asymmetric cryptography refers to the type and purpose of the keys used. Symmetric cryptography (also called private key cryptography) is characterized by the use of a single key for both encryption and decryption. This generally leads to the operations of encryption and decryption having a much simpler algorithmic structure and requiring relatively small keys. Furthermore, the operations involved are generally simple computational primitives like the XOR (Exclusive-OR) operator, or some permutations of the input, or bit shifts, among others. Both these factors contribute to the relative speed and minimal computational cost of symmetric algorithm. However, this can only be used when the sender and receiver possess the same shared secret key before secure communication begins. They may do this in a number of ways; physically meeting up to exchange keys, sending keys by post, or using some other protocol to exchange keys. This struggle to exchange keys is a microscopic reflection of the larger problem of secure communication that cryptography tries to solve.
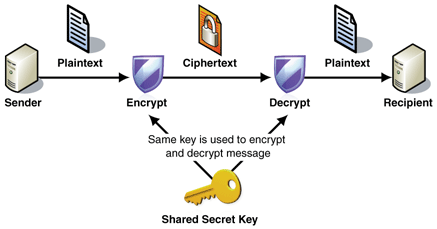 [5] The process of symmetric encryption
[5] The process of symmetric encryption
Asymmetric cryptography (also called public-key cryptography) involves two keys; a public key and a private key. As the names suggest, the public key is distributed publicly. It is not to be kept secret, and anyone can gain access to it. The private key, on the other hand, must be guarded at all times, as the security of the entire process relies on this guarantee. There are two modes of operation, both of which have their uses.
-
In the first mode, the public key is used to encrypt a message, which can then only be decrypted by the corresponding private key. This ensures that anybody can send a message securely to the holder of a particular private key, and rest assured that an eavesdropper who intercepts the message will not be able to extract useful information from it.
-
The second mode of operation is useful when you wish to ensure that a particular message comes from a particular person; a signature of sorts. Here, the private key is used to encrypt a message which can only be decrypted by the corresponding public key. If you are able to use Alice’s public key to decrypt a message sent to you, that acts as a guarantee that the message was sent by Alice, since nobody else has Alice’s private key, and hence would not be able to generate a ciphertext that can be decrypted by Alice’s public key.
The algorithms used to implement asymmetric cryptographic protocols make use of some rather heavy mathematical machinery, as a result of which the techniques they give rise to are computationally more complex than the techniques of symmetric cryptography. They are, therefore, more useful when the messages involved are short in length.
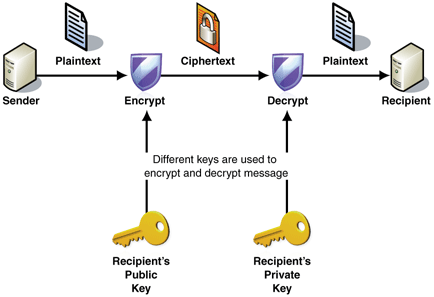 [5] The process of asymmetric encryption
[5] The process of asymmetric encryption
This leads to a natural use of asymmetric algorithms in solving the problem of key exchange we encountered above. Consider two parties, Alice and Bob, who wish to communicate securely. Both parties have their respective private keys $K_A$ and $K_B$, as well as their public keys $P_A$ and $P_B$. It would be inefficient to directly use the participants’ public and private keys to encrypt all communications between them in an asymmetric manner, owing to the relatively large computational cost of doing so. However, Alice can create a short random string $S$, which she encrypts using her private key and sends to Bob. Bob, who has Alice’s public key, can use it to decrypt Alice’s message and recover the string $S$, which they can then use as a shared private key to encrypt subsequent communications in an efficient manner using a symmetric encryption algorithm. This description offers a high level view of how symmetric and asymmetric algorithms work together to form the basis of secure communications today, although a number of details are absent (in particular, the problems of authenticating the participants and of message integrity are not considered here, although they are solved problems with well-known protocols).
One-Time Pad
In most discussion of cryptography, the one-time pad is introduced before more sophisticated ciphers, simply because it is considered more fundamental, and because it’s operation is much simpler than the methods discussed above. Here, it seems appropriate to discuss the one-time pad and its security implications after discussing other ciphers, as it allows for greater flexibility in contrasting the security properties of the two. The discussion of the one-time pad is simplest in the case where messages are simply bit streams of some length $n$. The ciphertext, the plaintext, and the key are all of this form. Given this, the key for a one-time pad is simply a perfectly random bit stream of length $n$. The encryption procedure consists of generating, bit-by-bit, the bitwise sum of the plaintext with the corresponding bit in the key, a process that is equivalent to the bitwise addition modulo 2 of the two bit streams. Given the random nature of the key, this is equivalent to randomly flipping bits of the plaintext. To make the procedure clearer, an example plaintext, key, and corresponding ciphertext are shown below:
Decryption is just as simple; the exact same process is performed, using the ciphertext and key as input this time. The preceding ciphertext is reused in the following example:
At a high level, the security of the above scheme relies on the fact that given a ciphertext $m$, it is possible that the ciphertext was generated by any possible plaintext. Under the appropriate choice of key, any plaintext encrypts to $m$. In fact, the required key is simply the bitwise addition modulo 2 of the ciphertext and the target plaintext. Therefore, there is no reason to prefer one plaintext over another; every possible plaintext is equally likely to give rise to $m$ under the appropriate choice of key. An adversary that possesses only the ciphertext has, in information-theoretic terms, no additional advantage; he knows no more about the plaintext than he did before he obtained the ciphertext. This property is formalized in a notion called perfect secrecy, which only one time pads are have, as proved by Shannon in his seminal paper [6].
The key property of the one-time pad, then, is this: the one-time is provably secure, a property not shared by any other encryption scheme. The most we can say about the symmetric and asymmetric methods introduced above is that they have not yet been proven insecure, a very important distinction, which leaves room for mathematical or other theoretical breakthroughs to find insecurities in them. If mathematical advances were to render trivial the problems whose difficulty public key cryptography relies upon, for instance, all of the current key distribution architecture would be rendered useless. The one-time pad is similar to quantum key distribution in that when carried out properly, quantum key distribution is provably secure; it is physically impossible for an eavesdropper to obtain information about the derived shared key. Of course, both security properties (in the one-time pad case as well as the QKD case) rely on the correctness of the implementation of the scheme. Mistakes in carrying out either protocol leave room for disastrous consequences, in some cases completely destroying the safety of the system used. For instance, a cardinal mistake in implementing a one-time pad is key reuse. If the same key is used to encrypt multiple messages, it becomes possible for an adversary in possession of multiple ciphertexts encrypted with the same key to derive the key, breaking the system completely. The security guarantee, then, rests on the single-use property of keys. In practice, this requirement, combined with the fact that one-time pad keys are as long as the message themselves, present an almost insurmountable obstacle to their widespread use. If Alice and Bob had some secure mechanism by which they could exchange one-time pad keys, they could just as easily exchange the message itself, since the key is just as long as the message. This is why, traditionally, asymmetric key cryptography is implemented; it can be leveraged for key exchange, after which the exchanged keys can be utilized in a symmetric key scheme for secure communication. QKD provides a solution to this quandary, enabling provably secure key exchange, which can then be used to encrypt messages securely using the one-time pad. The combination of QKD and one-time pads provides a provably secure form of encryption, something previously thought to be a mere pipe dream and standing as an ultimate stronghold of encryption that will weather theoretical advances, whether mathematical or computational.
Bibliography
- R. P. Feynman, “Simulating physics with computers,” Int. J. Theor. Phys., vol. 21, no. 6-7, pp. 467–488, 1982.
- H. Zhu, “Survey of computational assumptions used in cryptography broken or not by Shor’s algorithm,” 2001.
- P. W. Shor, “Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer,” SIAM J. Sci. Stat. Comput., vol. 26, p. 1484, 1995.
- L. K. Grover, “A fast quantum mechanical algorithm for database search,” Proceedings, 28th Annu. ACM Symp. Theory Comput., pp. 212–219, 1996.
- Microsoft Corporation, “Data Confidentiality,” vol. 650720. pp. 1–4, 2005.
- C. E. Shannon, “Communication theory of secrecy systems,” Bell Syst. Tech. J., vol. 28, no. July, pp. 656–715–656–715, 1949.
Footnotes
-
The notation $o(1)$ suggests a quantity that tends to $0$ as the input size increases ↩
-
As reported by Vehent, J. here: https://jve.linuxwall.info/blog/index.php?post/TLS_Survey ↩